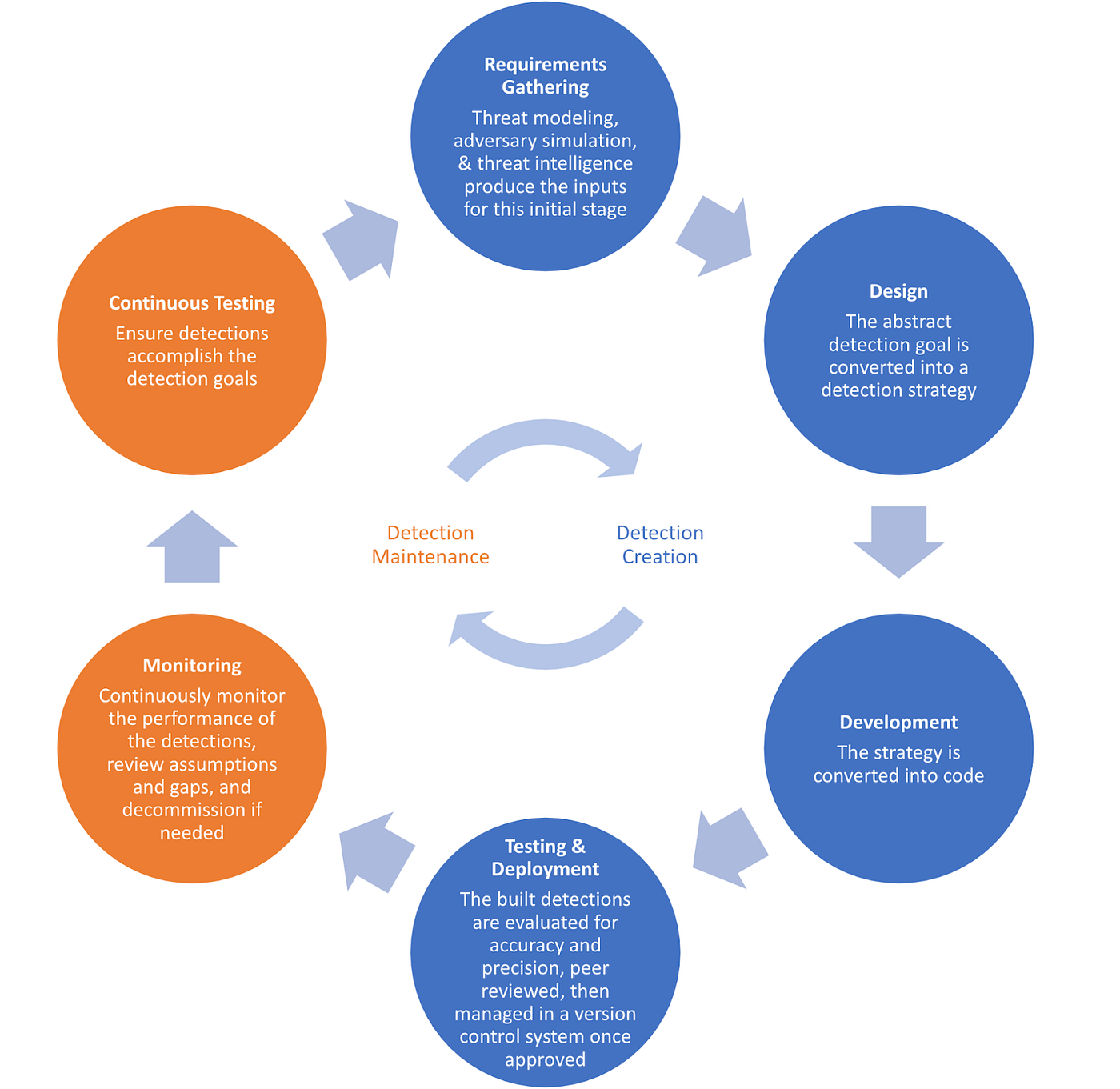
Detection Development Lifecycle
The Detection Engineering Development Lifecycle consists of six phases:
- Requirements Gathering
- Design
- Development
- Testing and Deployment
- Monitoring
- Continuous Testing
The process values reducing low fidelity detection, false positives and alert fatigue.
Prioritization is based on Risk Assessment, Threat Intelligence and aided by Detection Coverage Metrics. This allows for strategic planning, resource allocation and effective work delegation. For more details, please have a look at Detection Backlog Prioritization
Every organization is unique and implementations will vary. This should be a living document that you regularly update and improve as you face changes and make improvements.
Creating a robust lifecycle is not free of challenges as it will require the team to forge strong partnerships with stakeholders, establish roles and responsibilities, and have resources to support these processes.
Requirements Gathering
Any team with a role in protecting the enterprise can submit a request to the Detection team, usually candidates are:
- Product and Corporate Security
- Threat Intelligence
- Incident Response
- Audit and Compliance
- Red Team
- Threat Detection (internal)
Product and Corporate Security is added to this list as it can provide very useful, give sufficient resources, to work closely and early with these teams aiding in:
- Risk Identification & Mitigation
- Logging requirements
- Threat Modelling
- Identifying Detection Opportunities
- Maximizing Detection/Response feasibility & efficacy
As the name already suggests, all relevant information is collected during this phase, such as, but not limited to:
- Detection Goal
- Target System and its Function/Purpose
- Vulnerability
- Risk
- Threat Model
- Desired Alerting Methods (E-Mail, Slack, Teams, Jira, etc)
After all requirements and metadata has been collected we move on to prioritization, this is based on Risk Assessment and Threat Intelligence.
Design
During this phase, the goal is converted into a Detection Strategy, using the Alerting and Detection Strategy Framework, and peer reviewed by the Incident Response team, as they are the customer at the end of the day.
The review allows the response team to influence the detection, especially when it comes to making the detection easy to respond to, giving them time to prepare playbooks for triage and just general awareness/transparency.
Development
Once the Detection Strategy is reviewed, the actual detection query is developed while following concepts like Defense in Depth, Pyramid of Pain, Capability Abstraction, Detection Spectrum, Comprehensive Detection, Actionable Alerting, The Zen of Security Rules, etc.
During this phase it is important to use a standard template, ensuing every detection has a set of common fields and how to approach them. This will make maintenance and migration work easier in the future.
The template(s) should also link to any reference like:
- detection strategy
- threat intelligence sources
- related articles and blogs
- etc.
Also, tag as much as possible to things like:
- MITRE ATT&CK Tactics, Techniques, Sub-Techniques
- Platform (Windows, macOS, Unix, etc.)
- Data Sources the detection is relying upon
- Product and Corporate Security team's ID/Name
All this metadata will come in very handy for inquiries about your detection library, metrics, and audit.
For some inspiration and an example of how this could look like, have a look here: Detection Template
Testing and Deployment
During this phase, the detection with all its metadata and the play book is tested for:
- Accuracy: How accurate is the detection in identifying its goal?
- Durability: How easy would it be to bypass the detection?
- Alert Volume: How frequently does the detection trigger?
- Actionability: How easily can incident responders to act on the alert?
Usually, historical testing is conducted, by running the query against a feasible amount of past data.
To trigger a test alert, projects like Atomic Red Team are used or a custom offensive test case is written.
The decision if a detection meets the requirements is done together with the Incident Response team.
After testing is complete, the detections are peer-reviewed they're put into a central repository and managed with a version control system like Git.
After the detection is in production, maintenance begins, where a tight relationship with all stakeholders is required.
Monitoring
During this phase of the Detection its performance is continuously monitored, assumptions and gaps are review and decommissioning is kicked off when needed.
This is done through:
Detection Improvement Requests
These are requests to:
- fix bugs
- tune false positives (for more see Equilateral of Exclusion Risk)
- improve the responders ability to respond
- update the Alerting and Detection Strategy
- or even refactor the detection logic
This is also helpful for the Threat Detection team as it can be used to identify low fidelity detections and give us insights about our general quality/performance.
Detection Decommission Requests
Sometimes disabling an alert all together is the lesser evil than the alert fatigue caused by it.
These requests can be either temporary or permanent, but either way must follow documentation guidelines, ensuring the justification and supporting information can be recalled and understood in the future.
Detection Reviews
This process is used to eliminate detections that are too noisy or irrelevant by now.
This is especially important as the team matures and the library of detections accumulates.
In addition to the quality improvements, this is also a learning opportunity for team members. As they read and review other members detections, they might get the chance to work with a system or platform they've never seen before and can also get some insight into the way their colleagues approach detections.
A review of a detection consists of reconsidering its:
- Goal
- Scope
- Relevance
- Assumptions
- Detection Logic
- etc.
The outcome of a review is properly documented and can be:
- None, as the detection needs no change
- Detection Improvement Request
- Detection Decommission Request
Continuous Testing
We differentiate between two approaches here: automated Detection Validation and manual testing.
Automated regression testing is used to make sure any change to the detection, to for example exclude false positives, did not break the original goal.
Manual testing is done in collaboration with the Red Team through Purple Teaming. Here the goal is to break the detection logic, by for example using Command-Line Obfuscation, and then fix the bypass.
This is also a great chance to strengthen the relationship between Red and Blue, and also serves as a learning opportunity for both sides.
The output of continues testing is either none, a detection improvement request or a request for a new detection.
Benefits and Adoption
- Quality Having and following a robust Detection Development Lifecycle will lead to building high quality detections.
- Metrics Collecting metrics such as detection coverage and quality metrics, as well as defining key performance indicators, will help identify areas of improvement and drive program planning.
- Documentation “Code is the documentation” does not work because non-technical individuals are also consumers of internal processes. Quickly whipping together documentation around how the team went about building a detection or why a detection was disabled is painful and not scalable. Having sound documentation allows the Incident Response Team to better understand and triage the detection, reduce the time a Detection Engineer needs to review, understand and update a detection, and provide support for compliance and audit requests.
- Scale This is one of the first documents that a new Detection Engineer should read when joining the team. After reviewing, they should have a thorough understanding of the Threat Detection process end to end. This also keeps the team accountable and ensures processes are repeatable.
Relevant Note(s): Threat Hunting Loop Detection as Code